Gemini
Omni
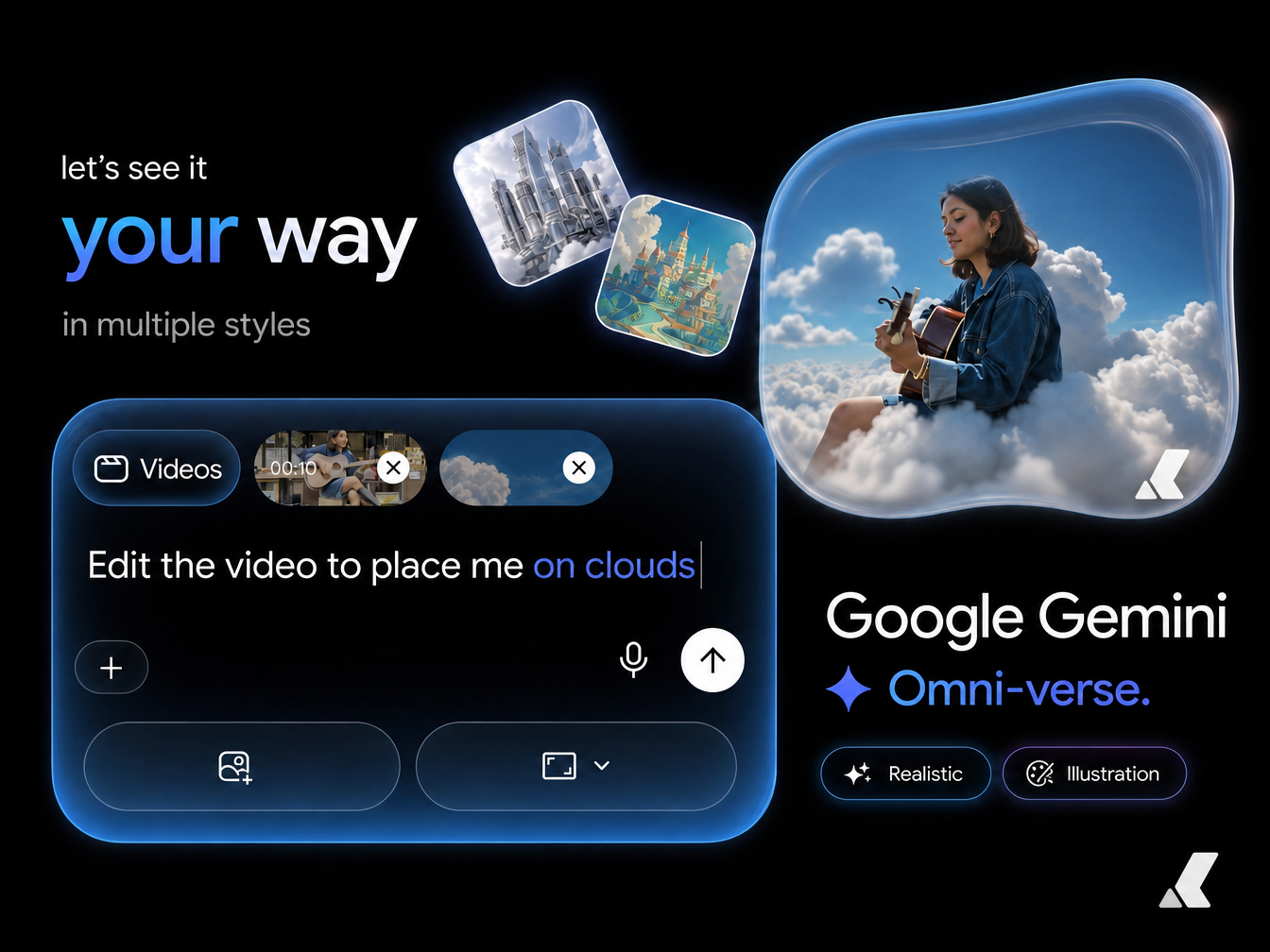
AI Video.
Google's first any-to-any multimodal AI model. Mix text, images, audio, and video in a single prompt to generate physics-accurate, character-consistent video clips. Now available on Kenerate AI.
Core Capabilities
Omni Capabilities.
Zero limits.
What makes Gemini Omni stand out from other AI models? It's the ultimate multimodal director, replacing tedious workflows with pure creative freedom.
Any-to-Any Input
Mix text, images, audio, and video in one prompt. The model reasons across them and returns one video that reflects every reference.
Conversational Editing
Every prompt builds on the last. Change a costume, retime an action, or swap a setting; the edit lands on the same shot, not a new one.
Character Consistency
Faces, clothing, and voices stay the same across every cut and edit. A subject from one shot is still recognizable in the next.
Physics & Real-world Reasoning
Gravity, weight, collisions, and fluids follow real-world rules. Cultural and historical scenes keep every detail intact.
Voice References for Audio
Drop in a voice sample and Gemini Omni keeps that voice steady across the generated clip. Perfect for consistent narrators.
SynthID Watermarking
Every Gemini Omni clip carries Google's invisible SynthID watermark. It's on by default and survives re-encoding and resizing.
How creators use Gemini Omni.
Multi-input storyboarding
Drop in a character image, a location photo, a music cue, and one beat. The model assembles the shot; follow-ups iterate on the scene seamlessly.
Marketing video
Educational explainers
Avatar & spokesperson
Social shorts
Generated with Omni.
Experience the multimodal capabilities of Gemini Omni Flash. Real generations showcasing physics, consistency, and prompt adherence.
"Text-to-Video: A cinematic wide shot of a futuristic Tokyo street, neon lights reflecting on wet pavement, realistic lighting."
Omni vs Veo vs Seedance.
While Veo 3.1 focuses on absolute photorealism and Seedance targets music syncing, Gemini Omni is the ultimate multimodal director for complex, multi-input reasoning and iterative editing.
Conversational editing.
Step by step.
Forget complex timeline editors. With Gemini Omni, you direct the video just like you're talking to a professional editor.
Gather your inputs
Collect the text prompt, reference images, audio voiceovers, or base video clips you want to use. Omni accepts them all at once.
Prompt the model
Describe what you want to happen. Omni uses its real-world reasoning to connect your multimodal inputs into a cohesive scene.
Generate video
In seconds, Omni Flash generates up to 10 seconds of high-fidelity video with embedded SynthID provenance.
Converse to edit
Not quite right? Just reply with an edit request (e.g., 'Make it raining instead'). Omni edits the existing shot without losing character consistency.
Frequently Asked Questions.
Everything you need to know about Google DeepMind's Gemini Omni model.
Pay once.
Create forever.
Buy credits a single time — they never expire. Use them across every tool on KenerateAI.
Starter
StandardPerfect for hobbyists exploring AI creative generation.
One-time · no subscription
Get Starter- Image Generation (All Models)
- Video Generation
- Music & Audio Creation
- 3D Model Generation
- Image Editing Studio
- LLM Chat Access
- Standard Speed
- Community Support
Creator
FastGreat for content creators who need consistent output.
One-time · no subscription
Get Creator- Everything in Starter
- Fast Generation Speed
- Priority Queue Access
- HD Video Export
- Advanced Image Editing
- Email Support
Professional
PriorityIdeal for professionals shipping creative work daily.
One-time · no subscription
Get Professional- Everything in Creator
- Priority Generation Speed
- All Premium AI Models
- 4K Video Generation
- Batch Generation
- Priority Support
Join the Community
Connect with thousands of creators, share your AI generations, participate in contests, and get direct support from the Kenerate AI team.
Join our DiscordDirect with Omni.
Join thousands of creators using Google DeepMind's any-to-any multimodal model. Generate, iterate, and converse your way to the perfect video.
No credit card required.
Includes SynthID protection.